Does turning the pages of an old book excite you? How about 3 million pages? That’s how many pages Eliza Zhang has scanned over her ten years with the Internet Archive, using Scribe, a specialized scanning machine invented by Archive engineers over 15 years ago. “Listening to 70s and 80s R&B while she works,” Wendy Hanamura writes at the Internet Archive blog, “Eliza spends a little time each day reading the dozens of books she handles. The most challenging part of her job? ‘Working with very old, fragile books.”
The fragile state and wide variety of the millions of books scanned by Zhang and the seventy-or-so other Scribe operators explains why this work has not been automated. “Clean, dry human hands are the best way to turn pages,” says Andrea Mills, one of the leaders of the digitization team. “Our goal is to handle the book once and to care for the original as we work with it.”
Raising the glass with a foot pedal, adjusting the two cameras, and shooting the page images are just the beginning of Eliza’s work. Some books, like the Bureau of Land Management publication featured in the video, have myriad fold-outs. Eliza must insert a slip of paper to remind her to go back and shoot each fold-out page, while at the same time inputting the page numbers into the item record. The job requires keen concentration.
If this experienced digitizer accidentally skips a page, or if an image is blurry, the publishing software created by our engineers will send her a message to return to the Scribe and scan it again.
It’s not a job for the easily bored; “It takes concentration and a love of books,” says Internet Archive founder Brewster Kahle. The painstaking process allows digitizers to preserve valuable books online while maintaining the integrity of physical copies. “We do not disbind the books,” says Kahle, a method that has allowed them to partner with hundreds of institutions around the world, digitizing 28 million texts over two decades. Many of those books are rare and valuable, and many have been deemed of little or no value. “Increasingly,” writes the Archive’s Chris Freeland, “the Archive is preserving many books that would otherwise be lost to history or the trash bin.”
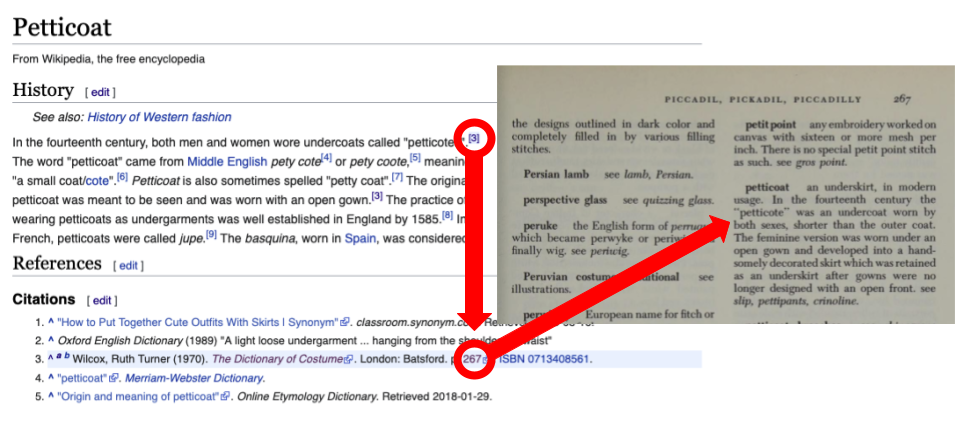
In one example, Freeland cites The dictionary of costume, “one of the millions of titles that reached the end of its publishing lifecycle in the 20th century.” It is also a work cited in Wikipedia, a key source for “students of all ages… in our connected world.” The Internet Archive has preserved the only copy of the book available online, making sure Wikipedia editors can verify the citation and researchers can use the book in perpetuity. If looking up the definition of “petticoat” in an out-of-print reference work seems trivial, consider that the Archive digitizes about 3,500 books every day in its 18 digitization centers. (The dictionary of costume was identified as the Archive’s 2 millionth “modern book.”)
Libraries “have been vital in times of crisis,” writes Alistair Black, emeritus professor of Information Sciences at the University of Illinois, and “the coronavirus pandemic may prove to be a challenge that dwarfs the many episodes of anxiety and crisis through which the public library has lived in the past.” A huge part of our combined global crises involves access to reliable information, and book scanners at the Internet Archive are key agents in preserving knowledge. The collections they digitize “are critical to educating an informed populace at a time of massive disinformation and misinformation,” says Kahle. When asked what she liked best about her job, Zhang replied, “Everything! I find everything interesting…. Every collection is important to me.”
The Internet Archive offers over 20,000,000 freely downloadable books and texts. Enter the collection here.
Related Content:
Josh Jones is a writer and musician based in Durham, NC. Follow him at @jdmagness
Leave a Reply